SNMP Booster: How does it works¶
Overview¶
What is it¶
The SnmpBooster module allows Shinken Pollers to directly manage SNMP data acquisition. This is an all Python cross-platform SNMP module. It is tightly integrated with the Shinken Poller, Scheduler and Arbiter daemons to provide the best possible user experience.
Why use it¶
The SnmpBooster module is designed to be efficient and scalable. It has a flexible configuration method to make it easy to use with Shinken Monitoring Packs and the Shinken configuration generator genDevConfig.
This acquisition module was professionally designed and developed.
It is meant to be used by the discovery engine genDevConfig (v3.0.5 and newer) originally developed for the Cricket SNMP monitoring tool and converted for use with Shinken.
It is the only scalable SNMP v2c implementation for Shinken.
How does it work¶
Shinken Integration¶
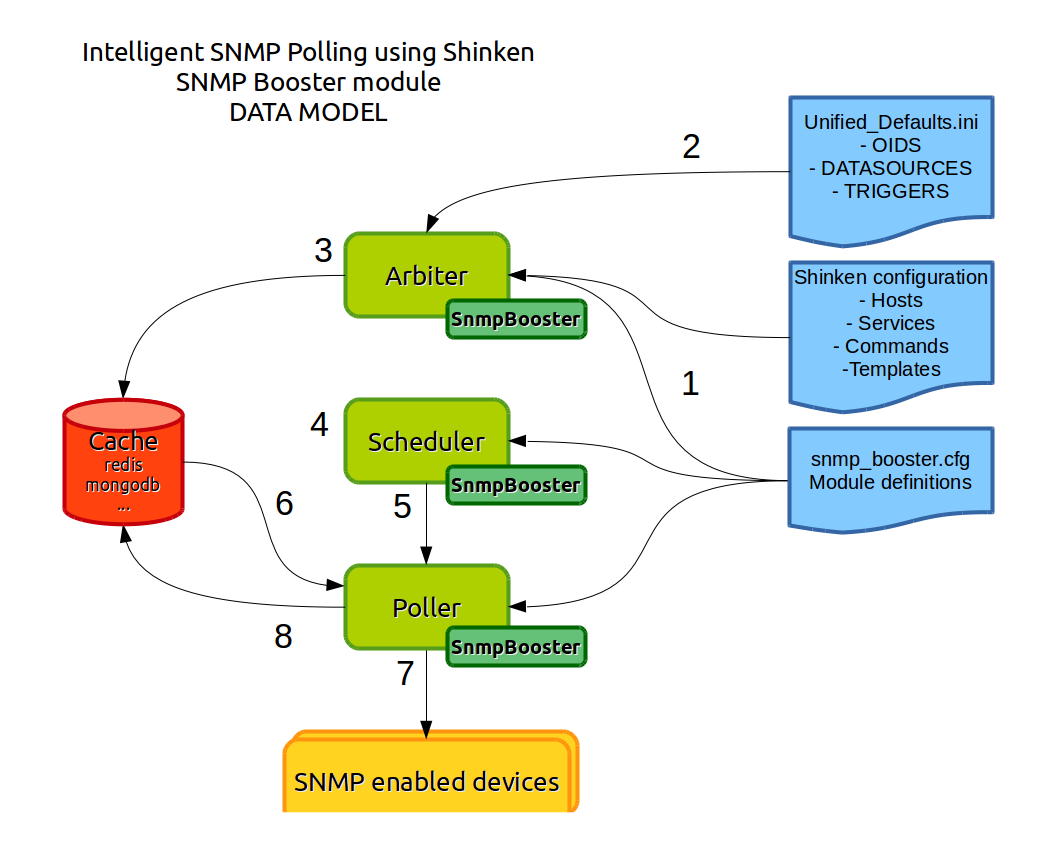
1 - The SnmpBooster Arbiter module reads the Shinken SnmpBooster configuration file(s). It reads the check commands and based on the values in the check commands that use the snmp_poller module it will creates a shared configuration cache using Redis. This permits to tie together Shinken Hosts and Services with the SNMP specific configuration. The Scheduler daemon schedules Host and Service checks as it normally does.
2 - The SnmpBooster Arbiter module computes Shinken configuration with datasource files (.ini files) and prepare datas for Redis
3 - The SnmpBooster Arbiter module stores an entry in Redis for each service defined in Shinken configuration
4 - The SnmpBooster Scheduler module determines which services will launch a SNMP requests and which will be a Redis requests
5 - Scheduler give tasks to pollers
6 - The SnmpBooster Poller module gets datas from Redis:
- It get the current service if it’s a Redis request
- It get all services from the host of the current service if it’s a SNMP request
7 - The SnmpBooster Poller module makes SNMP requests
8 - The SnmpBooster Poller module computes and stores collected datas from SNMP in Redis
Performance¶
SnmpBooster uses SNMP v2c getbulk or snmpgetnext for high efficiency. GetBulk and snmp get-next use a single request PDU to ask for multiple OIDs or even entire tables, instead of sending one request PDU per OID.
For example: A typical 24 port network switch with two uplinks might use 375 OIDS (8 OIDs per interface, plus general OIDs for chassis health, memory, cpu, fans, etc.). SnmpBooster will only require around 4 request PDUs instead of 375 request PDUs. Each PDU is a request packet which takes time to create, send get processed and return. More timeouts to manage, more connections, more impact on the remote device and more latency means much fewer checks per second.
SNMP Requests are multithreaded and each thread is responsible for gathering all data associated with a device.
SNMP Booster respectes all Shinken processing like retries, downtimes, etc for each monitored service.
A Redis data store is used to store collected data. All services associated to the same device will get their data from the Redis store. When data needs to be refreshed a single thread is chosen to contact the actual device to update the cache.
The SnmpBooster module supports automatic instance mapping for OIDs as well as static instances. (Ex. Based on the interface name it will figure out that the SNMP index(or instance) is 136. This is automatically handled by genDevConfig and SnmpBooster, no user input required. :-)
The generic SNMP configuration information is stored in the Shinken SnmpBooster INI files. There is a Defaults_unified.ini and a series of other Defaults files, one per discovery plugin for genDevConfig.
Important
genDevConfig plugins have all been converted to use the new dynamic instance mapping methods. You are now free to use most if not all Defaults*.ini files included with genDevConfig. 2012-10-28
Limitations¶
You should have your pollers with SnmpBooster in the same datacenter, as they need to be on the same machine with good connectivity to the active Redis server.
SnmpBooster is not compatible with distributed pollers in multiple datacenters, sorry, the current design of SnmpBooster uses a single centralized Redis instance for storing the timeseries data. For distributed datacenters to be supported, each poller+scheduler+Redis must be realm restrained, which is not the case today.
Design specification¶
SnmpBooster design specification and current development status.
Data model¶
The information required to define the data is split in two locations.
The first location is the host and service Shinken configuration (You need to generate or write this)
- Device specific information * IP addresses, host_names, device types, instance keys * A DSTEMPLATE must be referred to in the Service definition * A static SNMP instance could be referred to in the Service definition * An SNMP instance MAP function could be referred to in the Service definition * A TRIGGERGROUP could be refered to in the Service definition * A DS max could be refered to in the Service definition
The second location is SNMP Defaults.* templates. (Here you can create new devices or add new data sources)
- DATASOURCE information * SNMP OID * Type of data and how can it be interpreted (GAUGE, COUNTER, COUNTER64, DERIVE, DERIVE64, TEXT, TIMETICK) * Data format preparation (Scaling the data for example bits to bytes) * Is there an instance to append to the
- Instance MAP function * Mapping the instance dynamically using a function * Data or rules related to the mapping function
- DSTEMPLATEs to associate DATASOURCE to actual device classes * List of DATASOURCES associated with a, for example, Cisco 1900 router. Which in turn can be applied to a Shinken service
- TRIGGER and TRIGGERGROUPS to apply thresholding rules * Define triggers and associate them with a TRIGGERGROUP name that can be applied to a Shinken Service
A final location contains rules to build your Shinken configuration.
- genDevConfig plugins create Shinken configurations