Arbiter supervision of Shinken processes¶
Introduction¶
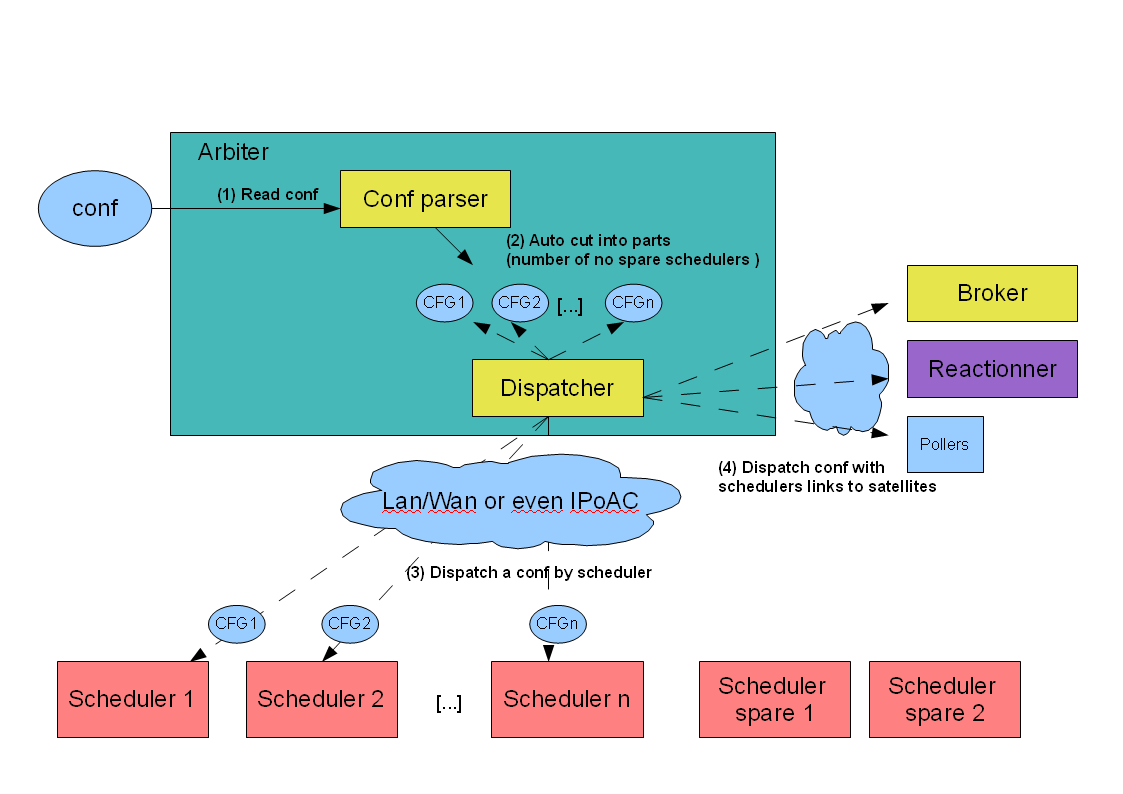
Nobody is perfect, nor are OSes. A server can fail, and so does the network. That’s why you can (should) define multiple processes as well as spares in the Shinken architecture.
Supervision method¶
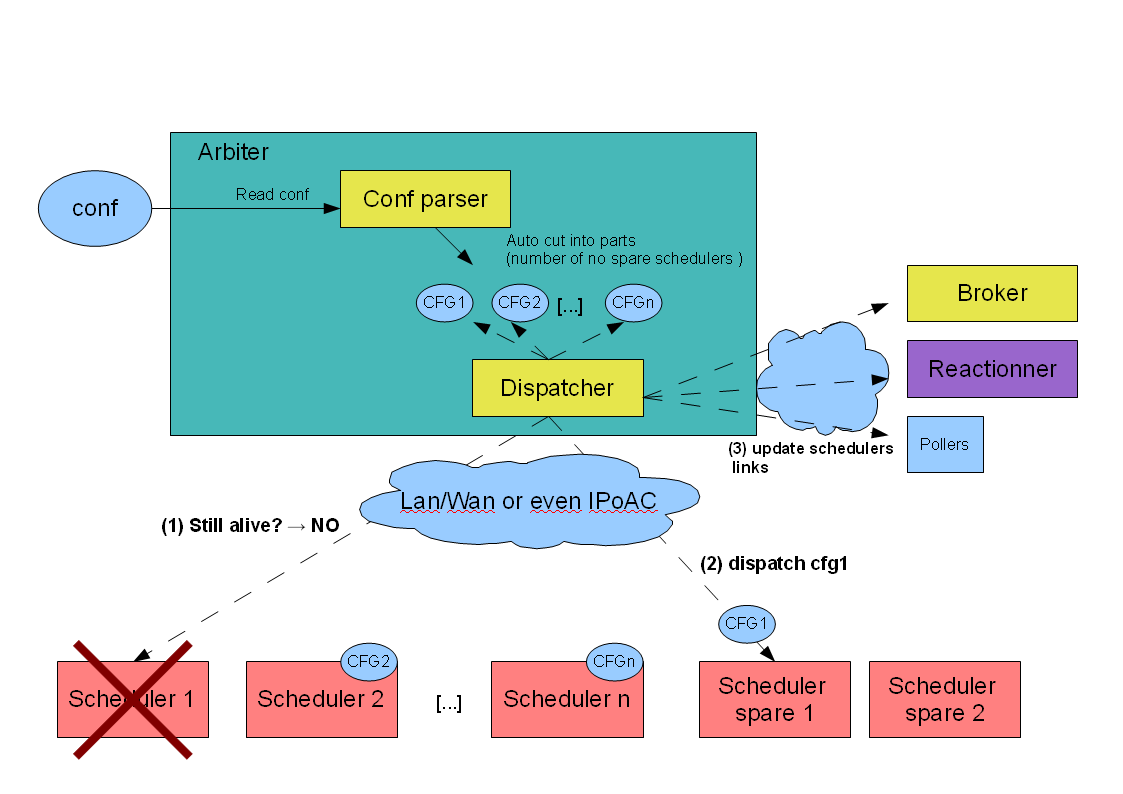
The Arbiter daemon constantly checks that every one is alive. If a node is declared to be dead, the Arbiter will send the configuration of this node to a spare one. Other satellites get the address of this new node so they can change their connections.
The case where the daemon was still alive but that it was just a network interruption is also managed: There will be 2 nodes with the same configuration, but the Arbiter will ask one (the old one) to become inactive.
The spare node that has become active will not preemptively fail back to the original node.
Adjusting timers for large configurations¶
Supervision parameters need to be adjusted with extra large configurations that may need more time to startup or process data. The arbiter periodically sends a verification to each process to see if it is alive. The timeouts and retry for this can be adjusted.
Timeout should be left at 3 seconds, even for large configuration. Health checks are synchronous. This is due to compatibility with Python 2.4. There will eventually become asynchronous as Python 2.6 support is dropped in the future. Retries should be multiplied as need. Data timeout should be left as is.
Important
TODO Put all of the arbiter supervisory parameters with formulas and examples.